Forecasting for COVID-19 has failed
John P.A. Ioannidis1, Sally Cripps2, Martin A. Tanner3
1 Stanford Prevention Research Center, Department of Medicine, and Departments of Epidemiology and Population Health, of Biomedical Data Science, and of Statistics, Stanford University, and Meta-Research Innovation Center at Stanford (METRICS), Stanford, California, USA
2 School of Mathematics and Statistics, The University of Sydney and Data Analytics for Resources and Environments (DARE) Australian Research Council, Sydney, Australia
3 Department of Statistics, Northwestern University, Evanston, Illinois, USA
Correspondence to: John P.A. Ioannidis, MD, DSc, Stanford Prevention Research Center, 1265 Welch Road, Medical School Office Building, Room X306, USA. E-mail: jioannid@stanford.edu
11 June 2020
COVID-19 is a major acute crisis with unpredictable consequences. Many scientists have struggled to make forecasts about its impact [1]. However, despite involving many excellent modelers, best intentions, and highly sophisticated tools, forecasting efforts have largely failed.
Experienced modelers drew early on parallels between COVID-19 and the Spanish flu [2] that caused >50 million deaths with mean age at death being 28. We all lament the current loss of life. However, as of June 8, total fatalities are ~410,000 with median age ~80 and typically multiple comorbidities.
Predictions for hospital and ICU bed requirements were also entirely misinforming. Public leaders trusted models (sometimes even black boxes without disclosed methodology) inferring massively overwhelmed health care capacity (Table 1) [3]. However, eventually very few hospitals were stressed, for a couple of weeks. Most hospitals maintained largely empty wards, waiting for tsunamis that never came. The general population was locked and placed in horror-alert to save the health system from collapsing. Tragically, many health systems faced major adverse consequences, not by COVID-19 cases overload, but for very different reasons. Patients with heart attacks avoided visiting hospitals for care [4], important treatments (e.g. for cancer) were unjustifiably delayed [5], mental health suffered [6]. With damaged operations, many hospitals started losing personnel, reducing capacity to face future crises (e.g. a second wave). With massive new unemployment, more people may lose health insurance. The prospects of starvation and of lack of control for other infectious diseases (like tuberculosis, malaria, and childhood communicable diseases for which vaccination is hindered by the COVID-19 measures) are dire [7,8].
Table 1: Some predictions about hospital bed needs and their rebuttal by reality: examples from news coverage of some influential forecasts
| State | Prediction made | What happened |
|---|---|---|
| New YorkNew York Times, April 10, 2020Forbes, May 26, 2020 | “Sophisticated scientists, Mr. Cuomo said, had studied the coming coronavirus outbreak and their projections were alarming. Infections were doubling nearly every three days and the state would soon require an unthinkable expansion of its health care system. To stave off a catastrophe, New York might need up to 140,000 hospital beds and as many as 40,000 intensive care units with ventilators.” 4/10/2020 | “But the number of intensive care beds being used declined for the first time in the crisis, to 4,908, according to daily figures released on Friday. And the total number hospitalized with the virus, 18,569, was far lower than the darkest expectations.” 4/10/2020“Here’s my projection model. Here’s my projection model. They were all wrong. They were all wrong.” Governor Andrew Cuomo 5/25/2020 |
| TennesseeNashville Post, April 6, 2020Tennessean, June 4, 2020 | “Last Friday, the model suggested Tennessee would see the peak of the pandemic on about April 19 and would need an estimated 15,500 inpatient beds, 2,500 ICU beds and nearly 2,000 ventilators to keep COVID-19 patients alive.” | “Now, it is projecting the peak to come four days earlier and that the state will need 1,232 inpatients beds, 245 ICU beds and 208 ventilators. Those numbers are all well below the state’s current health care capacity.”“Hospitals across the state will lose an estimated $3.5 billion in revenue by the end of June because of limitations on surgeries and a dramatic decrease in patients during the coronavirus outbreak, according to new estimates from the Tennessee Hospital Association.” 6/4/2020 |
| CaliforniaThe Sacremento Bee, March 31, 2020Medical Express, April 14, 2020 | “In California alone, at least 1.2 million people over the age of 18 are projected to need hospitalization from the disease, according to an analysis published March 17 by the Harvard Global Health Institute and the Harvard T.H. Chan School of Public Health… California needs 50,000 additional hospital beds to meet the incoming surge of coronavirus patients, Gov. Gavin Newsom said last week.” | “In our home state of California, for example, COVID-19 patients occupy fewer than two in 10 ICU beds, and the growth in COVID-19-related utilization, thankfully, seems to be flattening out. California’s picture is even sunnier when it comes to general hospital beds. Well under five percent are occupied by COVID-19 patients.” |
Modeling resurgence after reopening also failed. E.g. a Massachusetts General Hospital model [9] predicted over 23,000 deaths within a month of Georgia reopening. The actual number was only 896.
Table 2 lists some main reasons underlying this forecasting failure. Unsurprisingly, models failed when they used more speculation and theoretical assumptions and tried to predict long-term outcomes, e.g. using early SIR-based models to predict what would happen in the entire season. However, even forecasting built directly on data alone fared badly. E.g., the IHME failed to yield accurate predictions or accurate estimates of uncertainty [10] (Figure 1). Even for short-term forecasting when the epidemic wave has waned, models presented confusingly diverse predictions with huge uncertainty (Figure 2).
Table 2: Potential reasons for the failure of COVID-19 forecasting along with examples and extent of potential amendments
| Reasons | Examples | How to fix: extent of potential amendments |
|---|---|---|
| Poor data input on key features of the pandemic that go into theory-based forecasting (e.g. SIR models) | Early data providing estimates for case fatality rate, infection fatality rate, basic reproductive number and other key numbers that are essential in modeling were inflated. | May be unavoidable early in the course of the pandemic, when limited data are available; should be possible to correct when additional evidence accrues about true spread of the infection, proportion of asymptomatic and non-detected cases, and risk-stratification. Investment should be made in the collection, cleaning and curation of data. |
| Poor data input for data-based forecasting (e.g. time series) | Lack of consensus as to what is the ‘ground truth” even for seemingly hard-core data such as daily the number of deaths. They may vary because of reporting delays, changing definitions, data errors, and more reasons. Different models were trained on different and possibly highly inconsistent versions of the data. | As above: investment should be made in the collection, cleaning and curation of data. |
| Wrong assumptions in the modeling | Many models assume homogeneity, i.e. all people having equal chances of mixing with each other and infecting each other. This is an untenable assumption and in reality, tremendous heterogeneity of exposures and mixing is likely to be the norm. Unless this heterogeneity is recognized, estimated of the proportion of people eventually infected before reaching herd immunity can be markedly inflated | Need to build probabilistic models that allow for more realistic assumptions; quantify uncertainty and continuously re-adjust models based on accruing evidence. |
| High sensitivity of estimates | For models that use exponentiated variables, small errors may result in major deviations from reality | Inherently impossible to fix; can only acknowledge that uncertainty in calculations may be much larger than it seems. |
| Lack of incorporation of epidemiological features | Almost all COVID-19 mortality models focused on number of deaths, without considering age structure and comorbidities. This can give very misleading inferences about the burden of disease in terms of quality-adjusted life-years lost, which is far more important than simple death count. For example, the Spanish flu killed young people with average age of 28 and its burden in terms of number of quality-adjusted person-years lost was about 1000-fold higher than the COVID-19 (at least as of June 8, 2020). | Incorporate best epidemiological estimates on age structure and comorbidities in the modeling; focus on quality-adjusted life-years rather than deaths. |
| Poor past evidence on effects of available interventions | The core evidence to support “flatten-the-curve” efforts was based on observational data from the 1918 Spanish flu pandemic on 43 US cites. These data are >100-years old, of questionable quality, unadjusted for confounders, based on ecological reasoning, and pertaining to an entirely different (influenza) pathogen that had ~100-fold higher infection fatality rate than SARS-CoV-2. Even thus, the impact on reduction on total deaths was of borderline significance and very small (10-20% relative risk reduction); conversely many models have assumed 25-fold reduction in deaths (e.g. from 510,000 deaths to 20,000 deaths in the Imperial College model) with adopted measures | While some interventions in the broader package of lockdown measures are likely to have beneficial effects, assuming huge benefits is incongruent with the past (weak) evidence and should be avoided. Large benefits may be feasible from precise, focused measures (e.g. early, intensive testing with through contact tracing for the early detected cases, so as not to allow the epidemic wave to escalate [e.g. Taiwan or Singapore]; or draconian hygiene measures and thorough testing in nursing homes) rather than from blind lockdown of whole populations. |
| Lack of transparency | Many models used by policy makers were not disclosed as to their methods; most models were never formally peer-reviewed and the vast majority have not appeared in the peer-reviewed literature even many months after they shaped major policy actions | While formal peer-review and publication may take more time unavoidably, full transparency about the methods, and sharing of the code and data that inform these models is indispensable. Even with peer-review, many papers may still be glaringly wrong, even in the best journals. |
| Errors | Complex code can be error-prone and errors can happen even by experienced modelers; using old-fashioned software or languages (e.g. Fortran) can make things worse; lack of sharing code and data (or sharing them late) does not allow detecting and correcting errors | Promote data and code sharing; use up-to-date tools and processes that minimize the potential for error through auditing loops in the software and code. |
| Lack of determinacy | Many models are stochastic and need to have a large number of iterations run, perhaps also with appropriate burn-in periods; superficial use may lead to different estimates | Promote data and code sharing to allow checking the use of stochastic processes and their stability. |
| Looking at only one or a few dimensions of the problem at hand | Almost all models that had a prominent role in decision-making focused on COVID-19 outcomes, often just a single outcome or a few outcomes (e.g. deaths, or hospital needs). Models prime for decision-making need to take into account the impact on multiple fronts (e.g. other aspects of health care, other diseases, dimensions of the economy, etc.) | Interdisciplinarity is desperately needed; since it is unlikely that single scientists or even teams can cover all this space, it is important for modelers from diverse ways of life to sit on the same table. Major pandemics happen rarely and what is needed are models which fuse information from a variety of sources. Information from data, from experts in the field, from past pandemics, need to fused in a logically consistent fashion if we wish to get any sensible predictions. |
| Lack of expertise in crucial disciplines | The credentials of modelers are sometimes undisclosed; when they have been disclosed, these teams are led by scientists who may have strengths in some quantitative fields, but these fields may be remote from infectious diseases and clinical epidemiology; modelers may operate in subject matter vacuum | Make sure that the modelers’ team is diversified and solidly grounded in terms of subject matter expertise. |
| Groupthink and bandwagon effects | Models can be tuned to get desirable results and predictions, e.g. by changing the input of what are deemed to be plausible values for key variables. This is especially true for models that depend on theory and speculation, but even data-driven forecasting can do the same, depending on how the modeling is performed. In the presence of strong groupthink and bandwagon effects, modelers may consciously fit their predictions to what is the dominant thinking and expectations – or they may be forced to do so. | Maintain an open-minded approach; unfortunately, models are very difficult, if not impossible, to pre-register, so subjectivity is largely unavoidable and should be taken into account in deciding how much forecasting predictions can be trusted. |
| Selective reporting | Forecasts may be more likely to be published or disseminated, if they are more extreme | Very difficult to diminish, especially in charged environments; needs to be taken into account in appraising the credibility of extreme forecasts. |
Failure in epidemic forecasting is an old problem. In fact, it is surprising that epidemic forecasting has retained much credibility among decision-makers, given its dubious track record. Modeling for swine flu predicted 3,100-65,000 deaths in the UK [11]. Eventually only 457 deaths occurred [12]. The prediction for foot-and-mouth disease expected up to 150,000 deaths in the UK [13] and led to slaughtering millions of animals. However, the lower bound of the prediction was as low as only 50 deaths [13], a figure close to the eventual fatalities. Predictions may work in “ideal”, isolated communities with homogeneous populations, not the complex current global world.
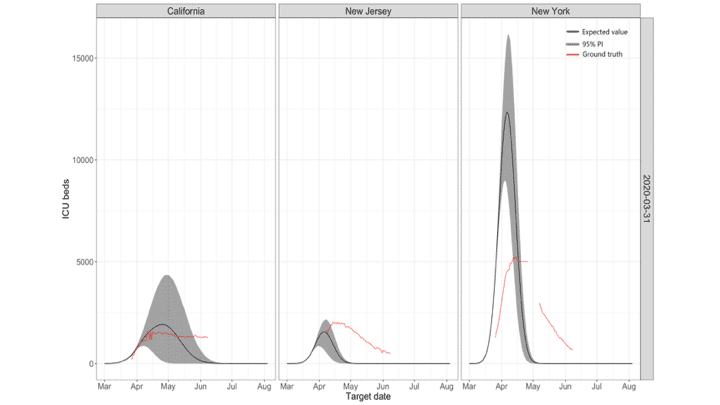
Figure 1: Predictions for ICU beds made by the IHME models on March 31 for three states, California, New Jersey and New York. For New York the model over predicted enormously, and then it under predicts. For New Jersey, a neighboring state, the model started well but then it under predicts, while for California it predicted a peak which never eventuated.
Despite these obvious failures, epidemic forecasting continued to thrive, perhaps because vastly erroneous predictions typically lacked serious consequences. Actually, erroneous predictions may have been even useful. A wrong, doomsday prediction may incentivize people towards better personal hygiene. Problems starts when public leaders take (wrong) predictions too seriously, considering them crystal balls without understanding their uncertainty and the assumptions made. Slaughtering millions of animals in 2001 aggravated a few animal business stakeholders, most citizens were not directly affected. However, with COVID-19, espoused wrong predictions can devastate billions of people in terms of the economy, health, and societal turmoil at-large.
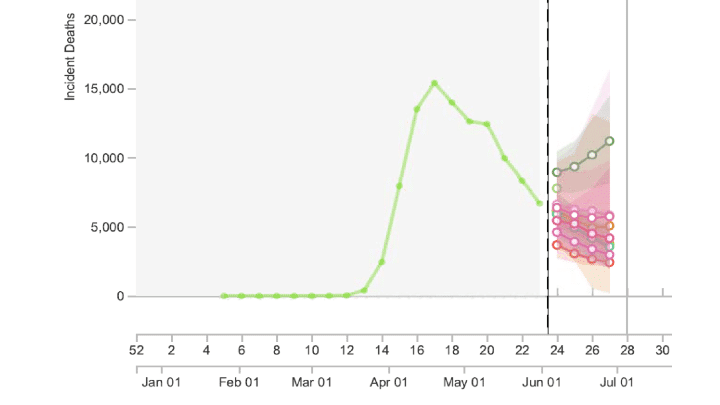
Figure 2: Snapshot from https://reichlab.io/covid19-forecast-hub/ (a very useful site that collates information and prediction from multiple forecasting models) as of 11.14am PT on June 3, 2020. Predictions for number of US deaths during week 27 (only ~3 weeks downstream) with these 8 models ranged from 2419 to 11190, a 4.5-fold difference, and the spectrum of 95% confidence intervals ranged from fewer than 100 deaths to over 16,000 deaths, almost a 200-fold difference.
Let’s be clear: even if millions of deaths did not happen this season, they may happen in the next wave, next season, or with some new virus in the future. A doomsday forecast may come handy to protect civilization, when and if calamity hits. However, even then, we have little evidence that aggressive measures which focus only on few dimensions of impact actually reduce death toll and do more good than harm. We need models which incorporate multicriteria objective functions. Isolating infectious impact, from all other health, economy and social impacts is dangerously narrow-minded. More importantly, with epidemics becoming easier to detect, opportunities for declaring global emergencies will escalate. Erroneous models can become powerful, recurrent disruptors of life on this planet. Civilization is threatened from epidemic incidentalomas.
Cirillo and Taleb thoughtfully argue [14] that when it comes to contagious risk, we should take doomsday predictions seriously: major epidemics follow a fat-tail pattern and extreme value theory becomes relevant. Examining 72 major epidemics recorded through history, they demonstrate a fat-tailed mortality impact. However, they analyze only the 72 most noticed outbreaks, a sample with astounding selection bias. The most famous outbreaks in human history are preferentially selected from the extreme tail of the distribution of all outbreaks. Tens of millions of outbreaks with a couple deaths must have happened throughout time. Probably hundreds of thousands might have claimed dozens of fatalities. Thousands of outbreaks might have exceeded 1,000 fatalities. Most eluded the historical record. The four garden variety coronaviruses may be causing such outbreaks every year [15,16]. One of them, OC43 seems to have been introduced in humans as recently as 1890, probably causing a “bad influenza year” with over a million deaths [17]. Based on what we know now, SARS-CoV-2 may be closer to OC43 than SARS-CoV-1. This does not mean it is not serious: its initial human introduction can be highly lethal, unless we protect those at risk.
Blindly acting based on extreme value theory alone would be sensible if we lived in the times of the Antonine plague or even in 1890, with no science to identify the pathogen, elucidate its true prevalence, estimate accurately its lethality, and carry out good epidemiology to identify which people and settings are at risk. Until we accrue this information, immediate better-safe-than-sorry responses are legitimate, trusting extreme forecasts as possible (not necessarily likely) scenarios. However, caveats of these forecasts should not be ignored [1,18] and new evidence on the ground truth needs continuous reassessment. Upon acquiring solid evidence about the epidemiological features of new outbreaks, implausible, exaggerated forecasts [19] should be abandoned. Otherwise, they may cause more harm than the virus itself.
Acknowledgement: The authors thank Vincent Chin for helpful discussions and for providing Figure 1.
Conflicts of interest: None.
REFERENCES
1. Holmdahl I, Buckee C. Wrong but useful — what Covid-19 epidemiologic models can and cannot tell us. N Engl J Med 2020 (in press).
2. https://www.imperial.ac.uk/mrc-global-infectious-disease-analysis/covid-19/report-9-impact-of-npis-on-covid-19/, accessed June 2, 2020.
3. IHME COVID-19 health service utilization forecasting team, Christopher JL Murray. Forecasting COVID-19 impact on hospital bed-days, ICU-days, ventilator-days and deaths by US state in the next 4 months. medRxiv 2020, doi: https://doi.org/10.1101/2020.03.27.20043752.
4. De Filippo O, D’Ascenzo F, Angelini F, et al. Reduced rate of hospital admissions for ACS during covid-19 outbreak in northern Italy. N Engl J Med 2020. doi:10.1056/NEJMc2009166.
5. Sud A, Jones ME, Broggio J, et al. Collateral damage: the impact on cancer outcomes of the covid-19 pandemic. medRxiv 2020 (preprint). https://www.medrxiv.org/content/10.1101/2020.04.21.20073833v2.full.
6. Moser DA, Glaus J, Frangou S, et al. Years of life lost due to the psychosocial consequences of covid-19 mitigation strategies based on Swiss data. medRxiv 2020 (preprint). https://www.medrxiv.org/content/10.1101/2020.04.17.20069716v2.a
7. Melnick T, Ioannidis JP. Should governments continue lockdown to slow the spread of covid-19? BMJ 2020;369:m1924.
8. Ioannidis JP. The totality of the evidence. Boston Review. In: http://bostonreview.net/science-nature/john-p-ioannidis-totality-evidence, last accessed June 2, 2020.
9. In: https://www.massgeneral.org/news/coronavirus/COVID-19-simulator, last accessed June 2, 2020.
10. Marchant R, Samia NI, Rosen O, Tanner MA, Cripps S. Learning as we go: An examination of the statistical accuracy of COVID19 daily death count predictions. medRxiv 2020 doi: https://doi.org/10.1101/2020.04.11.20062257
11. https://www.theguardian.com/uk/2009/jul/16/swine-flu-cases-rise-britain
12. UK government. The 2009 influenza pandemic review. In: https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/61252/the2009influenzapandemic-review.pdf. Last accessed June 2, 2020
13. Ferguson NM, Ghani AC, Donnelly CA, Hagenaars TJ, Anderson RM. Estimating the human health risk from possible BSE infection of the british sheep flock. Nature 2002;415:420-4.
14. Cirillo P, Taleb NN. Tail risk of contagious diseases. Nature Physics 2020; https://doi.org/10.1038/s41567-020-0921-x
15. Walsh EE, Shin JH, Falsey AR. Clinical impact of human coronaviruses 229E and OC43 infection in diverse adult populations. J Infect Dis 2013;208:1634-42.
16. Patrick DM, Petric M, Skowronski DM, et al. An outbreak of human coronavirus OC43 infection and serological cross-reactivity with SARS coronavirus. Can J Infect Dis Med Microbiol 2006;17(6):330.
17. Vijgen L, Keyaerts E, Moës E, Thoelen I, Wollants E, Lemey P, et al. Complete genomic sequence of human coronavirus OC43: Molecular clock analysis suggests a relatively recent zoonotic coronavirus transmission event. J Virol. 2005;79:1595–1604.
18. Jewell NP, Lewnard JA, Jewell BL. Predictive mathematical models of the COVID-19 pandemic: underlying principles and value of projections. JAMA. 2020. Epub 2020/04/17. doi: 10.1001/jama.2020.6585.
19. Ioannidis JP. Coronavirus disease 2019: The harms of exaggerated information and non-evidence-based measures. Eur J Clin Invest 2020;50:e13222.Share This:FacebookTwitterShareBy International Institute of Forecasters|June 14th, 2020|Forecasting News
